Logging at Scale - Part 2
Logging information from serving more than a billion requests per day
Continuing from the last post where we created a logging pipeline for storing and visualizing access logs in realtime, we faced some further issues with the said pipeline. In this post, I’ll try to build on that and get rid of some of these issues.
An expected unexpected problem
With the increase in number of requests during spikes in traffic, we were running quite a few instances. And that’s when we first encountered the AWS API request throttling. If we had 20-30 servers, each of them making an API request every 3 minutes, we were making around 400-600 requests per hour for information that necessarily wasnt even changing 20 times in that duration. Making 600 calls out of which less than 5% of the calls will have an actual change is very inefficient. It was an obvious oversight so we needed to improve on that.
We also couldn’t increase the cron timings, because we coudn’t afford our logstash cluster choking for too long. The thing is, even with a 200GB disk attached, we were filling out the disks every 20-25 mins and the data needed to be truncated in order to keep the the logs coming in without spending too much on storage on our reverse proxies. So, we needed all these requests to be responded to, but not necessarily by making AWS API calls for the data. Hence caching the data was a definite no-brainer. Also, any instance transition within the autoscaling group needed to be reflected as soon as possible. So, we needed to update our cache on every instance transition within the autoscaling group. This information was enough for us to come up with a simple straighforward solution.
The updated approach
An almost instant and obvious choice to store this cached data was redis. The key for each entry in redis would be the autoscaling group names for the DCs we operate in and the value would be the actual list of logstash server IPs from that autoscaling group. The simple python app that we were running would now simply do a redis lookup based on the autoscaling group name referenced in this request and respond with the appropriate list. We expect redis to always have the most recent values.
# snippet for implementing cached IPs with redis
REDIS_HOST = "localhost"
REDIS_PORT = 5050
@app.route('/logstash-ip')
def getip_logstash():
dc_id = request.args['dcid']
region_name = request.args['region']
res = get_ip_list(dc_id, region_name)
return res
def get_ip_list(dc_id, region_name):
r = redis.Redis(host=REDIS_HOST, port=REDIS_PORT)
key_name = ""
if dc_id == "some-dc":
key_name = "some-dc-asg-name"
elif dc_id == "some-other-dc":
key_name = "some-other-asg-name"
# and so on....
byte_ip_list = r.get(key_name)
if byte_ip_list != None:
ip_list = str(byte_ip_list.decode("utf-8"))
else:
send_alert("Failure in fetching ip list, empty value returned." + "\n falling back to aws api.", critical=True)
return getip_logstash(dc_id, region_name)
if ip_list == "" or ip_list[0] != "[":
send_alert("Failure in fetching ip list, it returned: " + ip_list + "\n falling back to aws api.", critical=True)
return getip_logstash(dc_id, region_name)
else:
return ip_list
def getip_logstash(dc_id, region_name):
asg_client = boto3.client('autoscaling', aws_access_key_id="key", aws_secret_access_key="secret", region_name=region_name)
ec2_client = boto3.client('ec2', aws_access_key_id="key", aws_secret_access_key="secret", region_name=region_name)
ec2 = boto3.resource('ec2', aws_access_key_id="key", aws_secret_access_key="secret", region_name=region_name)
asg_name = ""
if dc_id == "some-dc":
asg_name = "some-dc-asg-name"
elif dc_id == "some-other-dc":
asg_name = "some-other-asg-name"
# and so on....
try:
asg_response = asg_client.describe_auto_scaling_groups (AutoScalingGroupNames=[asg_name])
# List to hold the instance-ids and the Private IP Address
instance_ids, private_ip = [], []
for i in asg_response['AutoScalingGroups']:
for k in i['Instances']:
instance_ids.append(k['InstanceId'])
try:
for instance_id in instance_ids:
instance = ec2.Instance(instance_id)
ip = instance.private_ip_address
if ip:
private_ip.append(ip+":5044")
private_ip.sort()
except Exception as e:
send_alert("AWS API call failed; Reason: \n" + str(e), critical=True)
return "Failure"
return str(private_ip)
except Exception as e:
send_alert("AWS API call failed; Reason: \n" + str(e), critical=True)
return "Failure"
The next problem was to actually update the redis entries with the latest value on every state transition. We used lifecycle hooks to get both transition updates. Then we attached a SNS topic with this lifecycle hook so that this topic gets all the updates.

Then we created a lambda function which is subscribed to the SNS topic connected with our lifecycle hook, and hence gets triggered on every instance transition. This lambda function makes a call to our python server to update the redis keys with the latest entries. We wanted to keep everything internal within our VPC, so we ended up using SNS -> lambda -> python server instead of using a public HTTP call (SNS -> python-server (public endpoint)).
# lambda snippet for updating IP list on instance state transition
def lambda_handler(event, context):
http = urllib3.PoolManager()
sns = event["Records"][0]["Sns"]
message = json.loads(sns["Message"])
as_name = message["AutoScalingGroupName"]
dc = "dc id"
region = "region name"
url = 'http://<server-hostname>/update-ip-list?region=' + region + '&dcid=' + dc + '&as_name=' + as_name
r = http.request('GET', url)
print(instance, r.status, r.data)
return 0 The last and final step was adding an update-ip-list route, which would actually make the AWS api call to get all in-service instances for the given autoscaling group and update our redis keys. Everything else remained the same.
# update IP snipped in our python server
@app.route('/update-ip-list')
def set_ip_list():
dc_id = request.args['dcid']
region_name = request.args['region']
key_name = requests.args['as_name']
r = redis.Redis(host=REDIS_HOST, port=REDIS_PORT)
ip_list = getip_logstash(dc_id, region_name)
if ip_list != "Failure":
old_ip_list = str(r.get(key_name).decode("utf-8"))
try:
r.set(key_name, ip_list)
return "Success"
except Exception as e:
r.set(key_name, old_ip_list)
send_alert("Failure in updating redis list: " + str(e) , critical=True)
return "Failure"
else:
send_alert("Failure in fetching IP list: " + str(e) , critical=True)
return "Failure"So this is what the final architecture looks like:
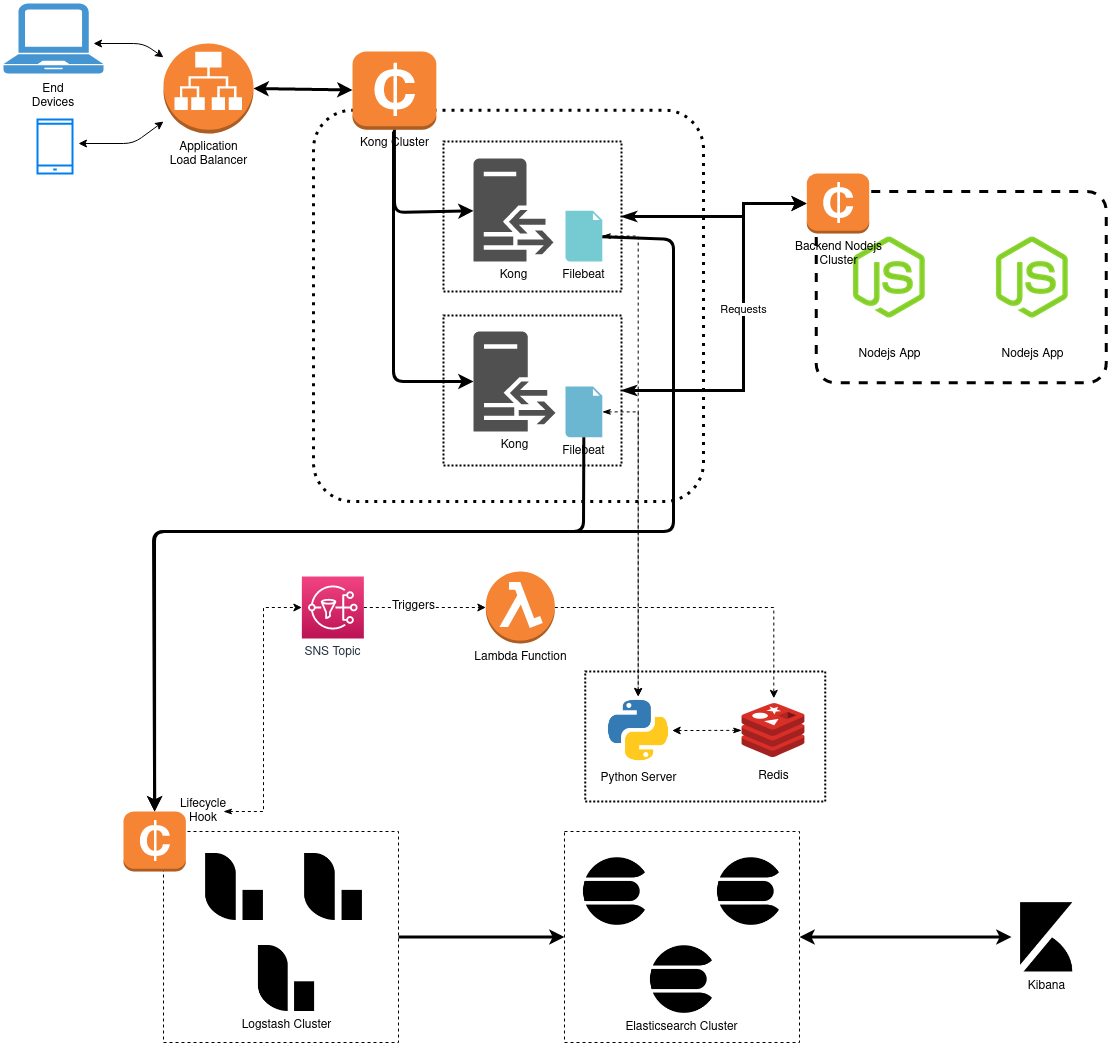
This certainly was an interesting problem to work on, and it did allow me to include and explore various different tech stacks. It still feels like this solution can be improved a lot and made much more efficient, and hopefully I can find an even better solution to solve this problem before the traffic scales even more!
Share this post
Twitter
Facebook
Reddit
LinkedIn
Email