Virtual File Systems (VFS)
What is VFS
The Virtual File System (also known as the Virtual Filesystem Switch) is the software layer in the kernel that provides the filesystem interface to userspace programs. It also provides an abstraction within the kernel which allows different filesystem implementations to coexist. VFS is an abstraction layer, it’s what makes “everything is a file” philosophy possible in linux.
Linux views all file systems from the perspective of a common set of objects. These objects are the superblock, inode, dentry, and file. At the root of each file system is the superblock, which describes and maintains state for the file system. The Filesystem is a hierarchical collection of data, organized into directories and files. Every object that is managed within a file system (file or directory) is represented in Linux as an inode.
- Linux requires a filesystem to implement 4 main system calls:
open(),read(),write(),close(). Rest is left to the implementer. - Linux doesnt strictly define what the filesystem is, it just provides an abstraction that allows the implementor to implement what they want to do.
- Reasons why it has a vast variety of Filesystems like
VFAT,NTFS,NFS,ext4,bttrfsetc. - Linux maintains sepereation b/w the filesystem and actual device. Thats why it can adopt new tech, eg. moving from HDD (rotational disks) to SSDs without affecting the abstraction.
High Level Architecture
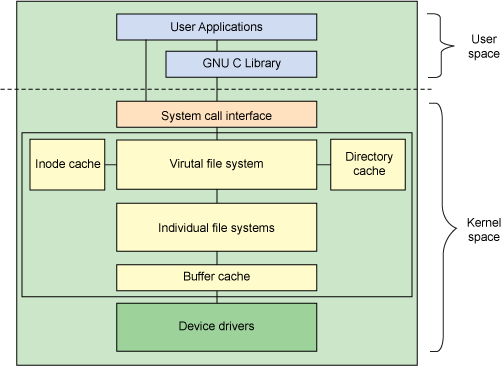
- User space contains the applications (for this example, the user of the file system) and the GNU C Library (
glibc), which provides the user interface for the file system calls (open,read,write,close). - The system call interface acts as a switch, funneling system calls from user space to the appropriate endpoints in kernel space.
- The VFS is the primary interface to the underlying file systems. This component exports a set of interfaces and then abstracts them to the individual file systems, which may behave very differently from one another.
- Each individual file system implementation, such as
ext4,bttrfs, and so on, exports a common set of interfaces that is used (and expected) by the VFS.
VFS Communicates with the following:
-
Memory Manager: This subsystem is responsible for managing the memory in the system. This includes implementation of virtual memory and demand paging, memory allocation both for kernel internal structures and user space programs, mapping of files into processes address space and many other cool things.
-
Process Scheduler: This subsystem handles the selection and removal of the queued/running processes. This can be non-preemptive, where a process’s resource cannot be taken before the process has finished running, or preemptive, where the OS assigns resources to a process for a predetermined period. The process switches from running state to ready state or from waiting for state to ready state during resource allocation.
-
Network Scheduler: Also called packet scheduler, queueing discipline (qdisc) or queueing algorithm, is an arbiter on a node in a packet switching communication network. It manages the sequence of network packets in the transmit and receive queues of the protocol stack and network interface controller. The network scheduler logic decides which network packet to forward next. The network scheduler is associated with a queuing system, storing the network packets temporarily until they are transmitted.
How VFS works
VFS sits between System Call’s layer and VFS implementer’s code, which defines the actual file system. VFS uses implementor’s code to reach the device driver, and then the device driver uses its own code to actually talk to the actual device. VFS is also called the “shim layer”.
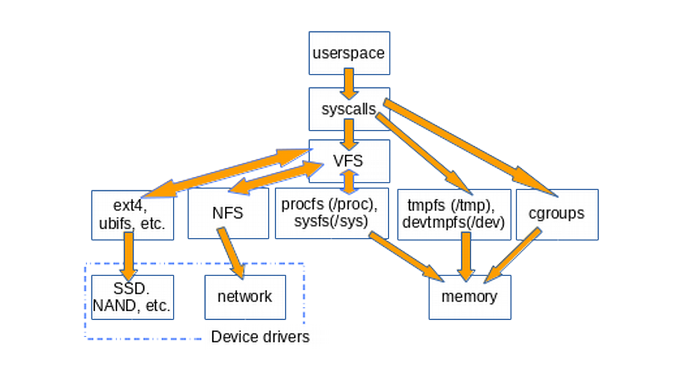
VFS promotes code reuse, abstraction and seperation of concerns
- Device driver takes care of the actual access to device.
- File system takes care of implementing the main system calls:
open(),read(),write(),close() - VFS takes care of syscalls and where to direct them.
- To add a new file system to Linux,
register_filesystemis called.
tmpfs used to implement /tmp, devtmpfs used to implement /dev, both created at runtime. Note that tmpfs and cgroups are “accessors”, they don’t go via VFS as they directly deal with memory.
Tmpfs
tmpfs is a file system which keeps all of its files in virtual memory. Everything in tmpfs is temporary in the sense that no files will be created on your hard drive. If you unmount a tmpfs instance, everything stored therein is lost.
**tmpfs puts everything into the kernel internal caches** and grows and shrinks to accommodate the files it contains and is able to swap unneeded pages out to swap space, if swap was enabled for the tmpfs mount. Since tmpfs lives completely in the page cache and optionally on swap, all tmpfs pages will be shown as “Shmem” in /proc/meminfo and “Shared” in free(1).
Uses of tmpfs
Generally, tasks and programs that run frequent read/write operations can benefit from using a tmpfs directory. Some applications can even receive a substantial gain by offloading some (or all) of their data onto the shared memory. Mounting directories as tmpfs can be an effective way of speeding up accesses to their files, or to ensure that their contents are automatically cleared upon reboot.
Some directories where tmpfs(5) is commonly used are /tmp, /var/lock and /var/run. There is always a kernel internal mount which you will not see at all. This is used for shared anonymous mappings and SYSV shared memory.
glibc 2.2 and above expects tmpfs to be mounted at /dev/shm for POSIX shared memory
The /proc filesystem
Proc is a pseudo filesystem that is generally mounted as /proc. It provides an interface into the kernel data structures. Files in this directory don’t actually exist, until you access them. Kernel actually provides the info in these files if you specifically “read” it. This Can be checked using file or ls -l.
The /proc/sys contains setting and configurations to be passed in kernel. The /proc has a directory for each running process, by the name of its pid.
procfs offers a snapshot into the state of linux kernel and the processes it controls in userspace. This is used by kernel to be able to present “state” in the filesystem, so that the userspace processes can get this info. eg top uses this to get it’s data.
The /sys filesystem
sysfs is a pseudo file system provided by the Linux kernel that exports information about various kernel subsystems, hardware devices, and associated device drivers from the kernel’s device model to user space through virtual files. By default it is mounted on /sys.
The linux kernel exposes all the devices, drivers, buses in the exact hierarchy in which it exists physically in the system through sysfs, and this hierarchy and grouping of similar types of objects (device, drivers, buses) is made possible through the “kobject” infra. A subsystem represents a set of kobjects. A kobject may belong to only one subsystem and a subsystem must contain only identically embedded kobjects.
Given that the sysfs entry for an kobject associated physical entity (device, driver, bus) is exposed as a file in the linux virtual filesystem, potential race conditions exist where the kobject is removed since a device got unloaded while the user space had opened the file for read/write. The kernel keeps a reference counter for kbjects; when counter reaches 0, kernel removes the kobject and reclaims any resources used by it.
Linux Protection Rings
Linux protection rings are mechanisms to protect data and functionality from faults (by improving fault tolerance) and malicious behavior (by providing computer security). It provide different levels of access to resources. A protection ring is one of two or more hierarchical levels or layers of privilege within the architecture. It is an extension of the privileged mode.
The idea is to aceess control structures in OS, based on ring srtructure. It is originally from multics os, they had 64 rings. Before rings, the user application crashing took everything down. Rings offered a means to protect the kernel and other applications from crashing when others crashed.
Rings works on principle of privilege. Outer ring has least privilege, inner one has most. In most linux system, there are 2 modes (rings): the userspace and kernel space. Syscalls are used to access resources in kernel from the userspace.
Linux uses Ring 0 and 3.
- Device drivers (demons) run inside kernel, different from daemons, which are system services.
- demon has a very specific structure.
Inodes and Files
The inode (index node) is a data structure in a Unix-style file system that describes a file-system object such as a file or a directory. Each inode stores the attributes and disk block locations of the object’s data. A directory is a list of inodes with their assigned names. The list includes an entry for itself, its parent, and each of its children.
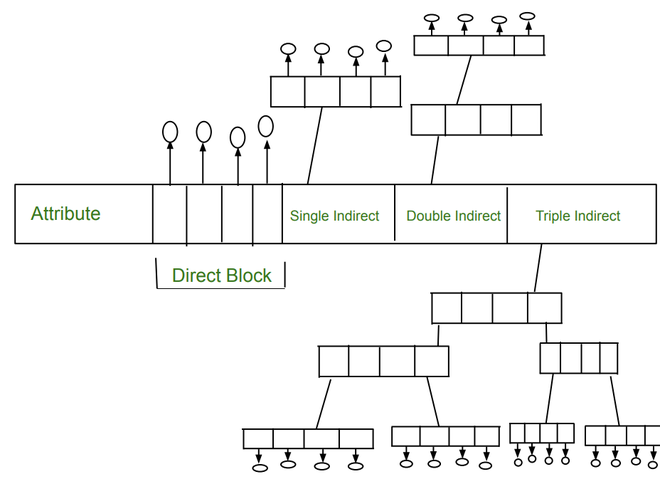
When a new file is created, an inode is allocated to store its metadata. Linux file systems use data blocks to store the actual content of files. These blocks are allocated on the disk to hold the file’s data. For small files, the data may be stored directly within the inode itself (known as direct blocks). For larger files, indirect blocks are used to manage the data blocks efficiently.
Files are stored in the form of blocks of a certain size. If a file is larger than this predetermined size, it’s broken down into chunks and stored in empty blocks wherever they’re available on the disk. Only the Metadata of files are stored in inodes.
Filenames are not stored in inodes, instead they are stored in the data portion of a directory. The file system creates an association in the directory where the file was created with name and inode (using link()). Hence the same file can be placed in multiple directories, using link(). To remove files from a directory, use unlink(). When you delete a file the unlink() system call removes the directory entry for the inode and marks it available. The data blocks themselves are not deleted.
Each inode contains a count of references of that file in directories. Each link increments and unlink decrements this count by one. Once this count reaches 0, the filesystem knows that this file can be discarded and storage is now free to be used by other processes. Each time a hard link is created the number of links increases. Soft links do not increase the number of links to a file or directory.
Inode structure contains the following attributes:
uidof the owner.guidof the owner.- Size of the file.
- File type: regular,directory,device etc.
- Date and Time of Last modification of the file data.
- Date and Time of Last access of file data.
- Date and Time of Last change of the I-node.
- Administrative information (permissions, timestamps, etc).
- A number of direct blocks (typically 12) that contains the first 12 blocks of the files.
There are some reserved inode numbers
- inode number 2: root directory
- inode 1: list of bad sectors
- inode 0: missing/null file
Theoretically, the maximum number of inodes a system can have is 2^32 or 4.3 billion inodes. But practically, the number is close to 1:16 KB of the system capacity. Empty files, devices, FIFOs, sockets, short symlinks consume an inode, but don’t consume a block.
An inode can contain direct or indirect points to blocks of data for a given file.
- Direct block means that the inode contains the block number of a block that contains the actual file data.
- A single indirect pointer that points to a disk block which in turn is used as an index block, if the file is too big to be indexed entirely by the direct blocks.
- Indirect block means that the inode contains the block number of a block that then contains further block numbers to read data from.
- A triple indirect pointer that points to an index block of index blocks of index blocks.
Dentry
Dentry is short for directory entry and is used to keep track of inode and filename information in a directory. They translate between names and inodes, for which a directory cache exists to keep the most-recently used around. This provides a very fast look-up mechanism to translate a pathname (filename) into a specific dentry. Dentries live in RAM and are never saved to disc: they exist only for performance.
Usually filenames are stored in a linear manner, that is why searching for a filename can take a long time. ext4 and XFS use Btrees to store filenames in directories, this allows for constant lookup times instead of linear lookup times.
ext filesystem creates a fixed number of inodes when the filesystem is formatted. If you run out of inodes you have to format the filesystem. XFS does not contain a fixed number of inodes, they are created on demand.
Superblock
The superblock is essentially file system metadata and defines the file system type, size, status, and information about other metadata structures. Superblock is located at a fixed position in the file system. The superblock is very critical to the file system and therefore is stored in multiple redundant copies for each file system.
Some of the information in a superblock is:
- Filesystem size
- Block size
- Empty and filled blocks
- Size and location of inode table
- Disk block map
For example, if the superblock of a partition, /var, becomes corrupt then the file system in question (/var) cannot be mounted by the operating system. Commonly in this event, you need to run fsck which will automatically select an alternate, backup copy of the superblock and attempt to recover the file system. The backup copies themselves are stored in block groups spread through the file system with the first stored at a 1 block offset from the start of the partition. This is important in the event that a manual recovery is necessary.
You can read superblock information using the command
dumpe2fs /dev/mount | grep -i superblock
File Descriptors
File descriptors are normally small non-negative integers that the kernel uses to identify the files accessed by a process. All open files are referred to by file descriptors. Whenever it opens an existing file or creates a new file, the kernel returns a file descriptor that we use when we want to read or write the file.
By convention, all shells open three descriptors whenever a new program is run: standard input, standard output, and standard error.
- The
open()function returns either a non-negative file descriptor if all is OK or−1if an error occurs. close()function closes the file descriptor.- When a process terminates, all of its open files are closed automatically by the kernel.
- Every open file has a “current file offset”, normally a non-negative integer that measures the number of bytes from the beginning of the file.
lseek(int fd, off_t offset, int whence): new file offset if OK, −1 on error.- The whence argument can be:
SEEK_SET: the file’s offset is set to offset bytes from the beginning of the fileSEEK_CUR: the file’s offset is set to its current value plus the offset. The offset can be positive or negative.SEEK_END: the file’s offset is set to the size of the file plus the offset. The offset can be positive or negative.
- To determine the current offset, seek zero bytes from the current position.
currpos = lseek(fd, 0, SEEK_CUR); - If the file descriptor refers to a pipe, FIFO, or socket, lseek sets
errnotoESPIPEand returns −1.
- The whence argument can be:
read(int fd, void *buf, size_t nbytes): number of bytes read, 0 if end of file, −1 on errorwrite(int fd, const void *buf, size_t nbytes): number of bytes written if OK, −1 on error
The lsattr command displays the attributes set on files or directories. These are special flags that control how the file system treats the files and directories, i.e., file system objects. The chattr allows changes the file attributes on a Linux file system. The operator ‘+’ causes the selected attributes to be added to the existing attributes of the files; ‘-’ causes them to be removed.
Types of “Files”
There are many types of files in Linux, as everything is a file.
-
“Regular” files are the normal, day to day kinda files storing some data on storage device.
-
Directories: storing inode and file associations and providing access to these files.
-
Symbolic link: This is a special type of file that doesn’t contain data, but a link to to other file. Writes/reads to the symlinks dont open this file, but open the file pointed to by the symlink.
-
Device Files: These emulate hardware devices as abstractions over actual devices, so we can use the same system calls to interact with these devices. CPU generally interacts and reads/writes data into the device registers, that is how they communicate. They might send interrupts which runs predetemined code that reads and writes from these registers. These device files allow us a higher level of abstraction.
-
Character device file:
- Generally these are actual hardware devices.
- Contains seperate input and output buffers, both FIFO. This means this has a capped storage, writes might fail in case the buffers are full.
- These contain seperate markes from where the data needs to be read from and a marker where data needs to be written.
- These are exposed on filesystems as
/devfiles. Some pseudo device files include:/dev/zero,/dev/random,/dev/null. - The devices in
/devdirectory do have an entry of device’s name and an associated inode. There is no data present in these files. Inode contains a special flag to signify these are a device file, not a regular file.
-
Block device file: These are generally devices with large storage areas. (eg. HDDs, SSDs)
- Represents the whole storage area of the storage device, i.e the first byte of file is byte0 of block0, and the last byte of file is last byte of last block.
- Something like databases might find it handy as the can manage the block device.
-
-
Pipes: Pipes are a way of IPC in the same system. A single FIFO buffer used for communication between processess. It is unidirectional in nature and hence we need to use seperate pipes for bi-directional reads. All data in pipes is present in memory, inodes dont point to blocks of data in case of pipes.
-
An anonymous pipe can be created using
pipe().pipe()returns two file descriptors, each pointing to different ends of the same pipe, first open for reading and the second one for writing. -
Named Pipes is an extension to the traditional pipe. These can be created by using
mkfifo, ormknod()which creates a filesystem node (file, device special file, or named pipe).mknod(name, type, deviceNum)where the type could beBLOCK,CHR,FIFOetc. Each device has a unique number associated with it.
-
-
Sockets: Sockets are a way of IPC in the same system or across different systems. A Unix domain socket aka UDS or IPC socket is a data communications endpoint for exchanging data between processes executing on the same host operating system. It is also referred to by its address family
AF_UNIX. The API for Unix domain sockets is similar to that of an Internet socket, but rather than using an underlying network protocol, all communication occurs entirely within the operating system kernel. Unix domain sockets may use the file system as their address name space. Processes reference Unix domain sockets as file system inodes, so two processes can communicate by opening the same socket. A network socket is a software structure within a network node of a computer network that serves as an endpoint for sending and receiving data across the network. The structure and properties of a socket are defined by an application programming interface (API) for the networking architecture.
Memory Mapped Files
A memory-mapped file is a segment of virtual memory that has been assigned a direct byte-for-byte correlation with some portion of a file or file-like resource. This resource is typically a file that is physically present on disk, but can also be a device, shared memory object, or other resource that an operating system can reference through a file descriptor. Once present, this correlation between the file and the memory space permits applications to treat the mapped portion as if it were primary memory.
The benefit of memory mapping a file is increasing I/O performance, especially when used on large files. For small files, memory-mapped files can result in a waste of slack space as memory maps are always aligned to the page size, which is mostly 4 KiB. Accessing memory mapped files is faster than using direct read and write operations for two reasons. Firstly, a system call is orders of magnitude slower than a simple change to a program’s local memory. Secondly, in most operating systems the memory region mapped actually is the kernel’s page cache (file cache), meaning that no copies need to be created in user space.
Another possible benefit of memory-mapped files is a “lazy loading”, thus using small amounts of RAM even for a very large file. Memory-mapping may not only bypass the page file completely, but also allow smaller page-sized sections to be loaded as data is being edited, similarly to demand paging used for programs.
The memory mapping process is handled by the virtual memory manager, which is the same subsystem responsible for dealing with the page file. Memory mapped files are loaded into memory one entire page at a time. The page size is selected by the operating system for maximum performance.
There are two types of memory-mapped files:
-
Persisted: Persisted files are associated with a source file on a disk. The data is saved to the source file on the disk once the last process is finished. These memory-mapped files are suitable for working with extremely large source files.
-
Non-persisted: Non-persisted files are not associated with a file on a disk. When the last process has finished working with the file, the data is lost. These files are suitable for creating shared memory for inter-process communications (IPC).
Partitions
Partitions are regions on the secondary storage. It is typically the first step of preparing a newly installed disk, before any file system is created. The disk stores the information about the partitions' locations and sizes in an area known as the partition table that the operating system reads before any other part of the disk. Each partition then appears to the operating system as a distinct “logical” disk that uses part of the actual disk.
Partitioning allows the use of different filesystems to be installed for different kinds of files. Separating user data from system data can prevent the system partition from becoming full and rendering the system unusable. Partitioning can also make backing up easier. A disadvantage is that it can be difficult to properly size partitions, resulting in having one partition with too much free space and another nearly totally allocated.
Formatting partitions with a filesystem creates uniformly sized blocks. Operations happens to the entire blocks. Data stored on these blocks (denoted by inodes). Theres a buffer for each block. The reads and writes are passed through these block buffers. The block is marked dirty when data is written to the buffer and it differs from the block on disk.
Share this post
Twitter
Facebook
Reddit
LinkedIn
Email