Short Notes: Memory Management
How the OS actually manages memory for all processes
Memory Management
The CPU can only access its registers and main memory. It cannot, for example, make direct access to the hard drive, so any data stored there must first be transferred into the main memory chips before the CPU can work with it. Device drivers communicate with their hardware via “interrupts” and “memory” accesses, sending short instructions.
For example, to transfer data from the hard drive to a specified location in main memory, the disk controller monitors the bus for such instructions, transfers the data, and then notifies the CPU that the data is there with another interrupt, but the CPU never gets direct access to the disk.
User processes must be restricted so that they only access memory locations that “belong” to that particular process. This is usually implemented using a base register and a limit register for each process. Every memory access made by a user process is checked against these two registers, and if a memory access is attempted outside the valid range, then a fatal error is generated.
Why Virtual Memory
- Not enough memory to run all programs concurrently with the memory requested.
- Program will leave holes in physical memory address space (fragmentation) once they are finished.
- No security if there’s direct access to physical memory, process could see all the physical memory and possibly coorrupt it.
- Physical memory uses fixed size memeory blocks.
- Segmentation uses variable sized memory blocks.
Logical Versus Physical Address Space
- The address generated by the CPU is a logical address, whereas the address actually seen by the memory hardware is a physical address.
- Addresses bound at compile time or load time have identical logical and physical addresses.
- Addresses created at execution time, however, have different logical and physical addresses.
- In this case the logical address is also known as a virtual address, and the two terms are used interchangeably.
- The set of all logical addresses used by a program composes the logical address space, and the set of all corresponding physical addresses composes the physical address space.
- The run time mapping of logical to physical addresses is handled by the memory-management unit, MMU.
- The MMU can take on many forms. One of the simplest is a modification of the base-register scheme described earlier.
- The base register is now termed a relocation register, whose value is added to every memory request at the hardware level.
- User programs never see physical addresses. User programs work entirely in logical address space, and any memory references or manipulations are done using purely logical addresses. Only when the address gets sent to the physical memory chips is the physical memory address generated.
Memory management handles:
-
Relocation
- No idea where program will be placed in memory, happens on execution.
- Before the program is loaded, address references are relative to the entry point of the program.
- Logical addresses are used, part of the logical address space, which are in turn translated to physical address space.
- Mapping b/w logical and physical memory is caaled the virtual memory.
sizeshows the linux size of the binary file, total memory required by the process is shown in decimal and hex.
-
Protection
- Checked during execution time.
- Kernel terminates the the program if it tries to access memory outside it’s granted locations, unless its a dynamic library.
-
Sharing
- IPC and shared memory; allows one or more processes to access shared memory or share data.
-
Logical Origanization
- Organized in linear fashion.
- Programs organized into modules which can be written and compiled independently.
- Different degress of protection can be given to different modules (read only, execute only).
- Modules can be shared across processes.
- Code sgement has read only attribute.
readelfcan help oanalyze process structure.
-
Physical Origanization
- Fixed partitioning - for code and libs compiled into the binary.
- Dynamic Partioning - for code adn libs needing memory in run time.
-
Rather than loading an entire program into memory at once, dynamic loading loads up each routine as it is called. The advantage is that unused routines need never be loaded, reducing total memory usage and generating faster program startup times.
-
With static linking library modules get fully included in executable modules, wasting both disk space and main memory usage, because every program that included a certain routine from the library would have to have their own copy of that routine linked into their executable code.
-
With dynamic linking, however, only a stub is linked into the executable module, containing references to the actual library module linked in at run time. This saves disk space, and if the code section of the library routines is reentrant, ( meaning it does not modify the code while it runs, making it safe to re-enter it ), then main memory can be saved by loading only one copy of dynamically linked routines into memory and sharing the code amongst all processes that are concurrently using it.
Memory Allocation
For memory allocation, OS keeps a list of unused (free) memory blocks (holes), and finds a hole of a suitable size whenever a process needs to be loaded into memory. There are many different strategies for finding the “best” allocation of memory to processes, including the three most commonly used:
- First fit: Search the list of holes until one is found that is big enough to satisfy the request, and assign a portion of that hole to that process. Whatever fraction of the hole not needed by the request is left on the free list as a smaller hole. Subsequent requests may start looking either from the beginning of the list or from the point at which this search ended.
- Best fit: Allocate the smallest hole that is big enough to satisfy the request. This saves large holes for other process requests that may need them later, but the resulting unused portions of holes may be too small to be of any use, and will therefore be wasted. Keeping the free list sorted can speed up the process of finding the right hole.
- Worst fit: Allocate the largest hole available, thereby increasing the likelihood that the remaining portion will be usable for satisfying future requests.
Simulations show that either first or best fit are better than worst fit in terms of both time and storage utilization. First and best fits are about equal in terms of storage utilization, but first fit is faster.
Swap Space
- Swap space is to substitute disk space for RAM memory when real RAM fills up and more space is needed.
- The kernel’s memory management detects blocks (pages) of memory in which the contents have not been used recently. It swaps enough of these relatively infrequently used pages of memory out to a special partition on the hard drive specifically designated for “paging” or “swapping”.
- Linux provides for two types of swap space:
- Swap partition: A standard disk partition that is designated as swap space by the
mkswapcommand. - Swap File: This is just a regular file that is created and preallocated to a specified size. Then the
mkswapcommand is run to configure it as swap space.
- Swap partition: A standard disk partition that is designated as swap space by the
- Swap partitions are preffered, kernel expects to be swapping to a block device. If the swapfile isn’t fragmented, it’s exactly as if there were a swap partition at its same location. Benefit of a dedicated swap partition is guaranteed unfragmentation.
Thrashing
- Thrashing occurs in a system with virtual memory when a computer’s real storage resources are overcommitted, leading to a constant state of paging and page faults, slowing most application-level processing.
- After initialization, most programs operate on a small number of code and data pages compared to the total memory the program requires. The pages most frequently accessed at any point are called the working set, which may change over time.
- When the working set is not significantly greater than the system’s total number of real storage page frames, virtual memory systems work most efficiently and an insignificant amount of computing is spent resolving page faults.
- As the total of the working sets grows, resolving page faults remains manageable until the growth reaches a critical point at which the number of faults increases dramatically and the time spent resolving them overwhelms the time spent on the computing the program was written to do.
- You might see that the CPU load is very high, perhaps as much as 30-40 times the number of CPU cores in the system.
- To prevent thrashing we must provide processes with as many frames as they really need “right now”, but how do we know what that is? The locality model notes that processes typically access memory references in a given locality, making lots of references to the same general area of memory before moving periodically to a new locality.
- The working set model is based on the concept of locality, and defines a working set window, of length delta. Whatever pages are included in the most recent delta page references are said to be in the processes working set window.
- The selection of delta is critical to the success of the working set model - If it is too small then it does not encompass all of the pages of the current locality, and if it is too large, then it encompasses pages that are no longer being frequently accessed.
Fragmentation
- All the memory allocation strategies suffer from external fragmentation. External fragmentation means that the available memory is broken up into lots of little pieces, none of which is big enough to satisfy the next memory requirement, although the sum total could.
- Internal fragmentation also occurs, with all memory allocation strategies. This is caused by the fact that memory is allocated in blocks of a fixed size, whereas the actual memory needed will rarely be that exact size.
- If the programs in memory are relocatable, (using execution-time address binding), then the external fragmentation problem can be reduced via compaction, i.e. moving all processes down to one end of physical memory. This only involves updating the relocation register for each process, as all internal work is done using logical addresses.
Segmentation
- Memory segmentation provides addresses with a segment number (mapped to a segment base address) and an offset from the beginning of that segment.
- A segment table maps segment-offset addresses to physical addresses, and simultaneously checks for invalid addresses, using a system similar to the page tables and relocation base registers.
Paging
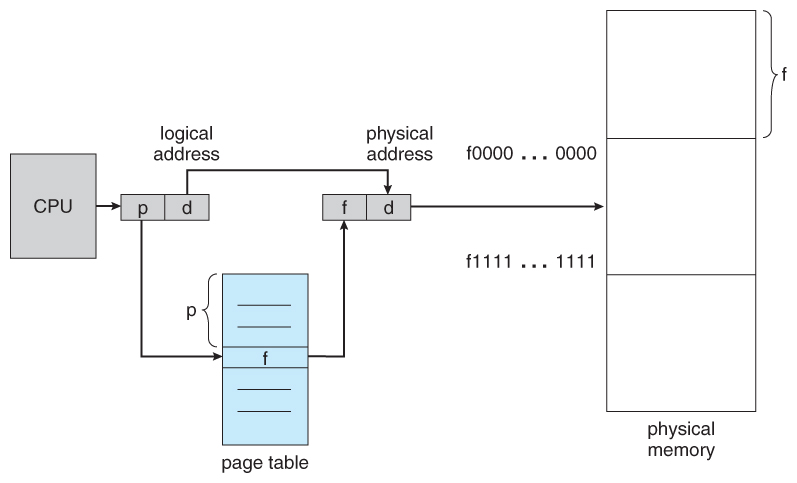
- Paging is a memory management scheme that allows processes physical memory to be discontinuous, and which eliminates problems with fragmentation by allocating memory in equal sized blocks known as pages.
- The basic idea behind paging is to divide physical memory into a number of equal sized blocks called frames, and to divide a programs logical memory space into blocks of the same size called pages.
- Any page (from any process) can be placed into any available frame.
- Pages are mapped to frames using a page table.
-
A logical address consists of two parts: A page number in which the address resides, and an offset from the beginning of that page.
-
The page table maps the page number to a frame number, to yield a physical address which also has two parts: The frame number and the offset within that frame.
-
Page numbers, frame numbers, and frame sizes are determined by the architecture, but are typically powers of two, allowing addresses to be split at a certain number of bits. For example, if the logical address size is
2^mand the page size is2^n, then the high-order m-n bits of a logical address designate the page number and the remaining n bits represent the offset. -
There is no external fragmentation with paging. All blocks of physical memory are used, and there are no gaps in between and no problems with finding the right sized hole for a particular chunk of memory. There is, however, internal fragmentation.
-
Page table entries (frame numbers) are typically 32 bit numbers, allowing access to
2^32physical page frames. If those frames are4 KBin size each, that translates to 16 TB of addressable physical memory. When a process requests memory (e.g. when its code is loaded in from disk), free frames are allocated from a free-frame list, and inserted into that process’s page table. -
Processes are blocked from accessing anyone else’s memory because all of their memory requests are mapped through their page table. There is no way for them to generate an address that maps into any other process’s memory space.
-
The operating system must keep track of each individual process’s page table, updating it whenever the process’s pages get moved in and out of memory, and applying the correct page table when processing system calls for a particular process.
-
Page lookups must be done for every memory reference, and whenever a process gets swapped in or out of the CPU, its page table must be swapped in and out too, along with the instruction registers, etc. It is therefore appropriate to provide hardware support for this operation, in order to make it as fast as possible and to make process switches as fast as possible also.
-
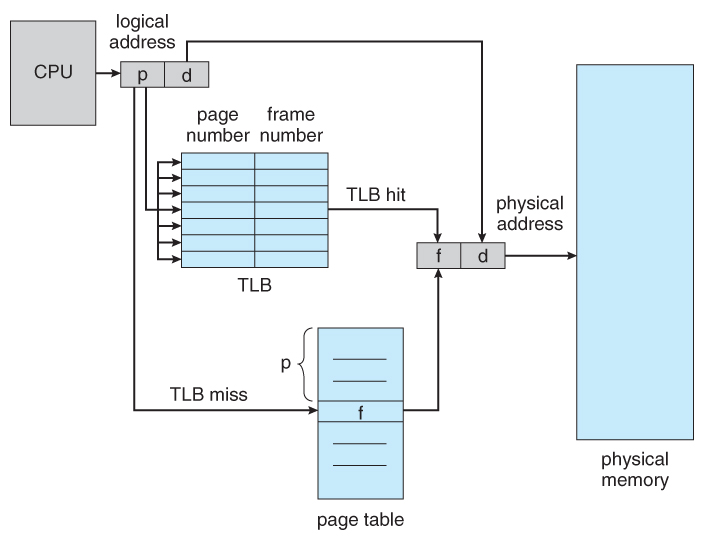
The page table is in the main memory, and to use it, a single register (called the page-table base register, PTBR) records where in memory the page table is located. Process switching is fast, because only the single register needs to be changed.
-
However memory access just got half as fast, because every memory access now requires two memory accesses - One to fetch the frame number from memory and then another one to access the desired memory location.
-
The solution to this problem is to use a very special high-speed memory device called the translation look-aside buffer, TLB. The benefit of the TLB is that it can search an entire table for a key value in parallel, and if it is found anywhere in the table, then the corresponding lookup value is returned.
-
In case of a table hit, it takes 1 cpu cycle to return the page address. If not, its a TLB miss and requires more cycles and then the frame is looked up from main memory and the TLB is updated. This generates an interrupt called page fault when page is not in memory.
-
If address requested has its invalid bit set, the program is killed. If it is valid then following happens:
- The kernel locates a free frame.
- It schedules disk I/O to load desired page into this new frame.
- When I/O is complete, OS updates the page table to show its frame location and mark it valid.
- CPU restarts the instruction that generated the page fault.
-
If the TLB is full, then replacement strategies range from least-recently used, LRU to random.
-
Some TLBs allow some entries to be wired down, which means that they cannot be removed from the TLB. Typically these would be kernel frames.
-
Some TLBs store address-space identifiers, ASIDs, to keep track of which process “owns” a particular entry in the TLB. This allows entries from multiple processes to be stored simultaneously in the TLB without granting one process access to some other process’s memory location. Without this feature the TLB has to be flushed clean with every process switch.
Demand Paging
The idea behind “demand paging” is that when a process is swapped in, its pages are not swapped in all at once. Rather they are swapped in only when the process needs them (on demand). This is termed a “lazy swapper”, although a pager is a more accurate term. Pages that are not loaded into memory are marked as “invalid” in the page table, using the invalid bit. (The rest of the page table entry may either be blank or contain information about where to find the swapped-out page on the hard drive.)
If a page is needed that was not originally loaded up, then a “page fault” trap is generated, which must be handled in a series of steps:
- The memory address requested is first checked, to make sure it was a valid memory request. If the reference was invalid, the process is terminated. otherwise, the page must be paged in.
- A free frame is located, possibly from a free-frame list.
- A disk operation is scheduled to bring in the necessary page from disk. (This will usually block the process on an I/O wait, allowing some other process to use the CPU in the meantime.)
- When the I/O operation is complete, the process’s page table is updated with the new frame number, and the invalid bit is changed to indicate that this is now a valid page reference.
- The instruction that caused the page fault must now be restarted from the beginning, (as soon as this process gets another turn on the CPU.)
In case of page replacement, there’s an extra disk write to the page-fault handling (page out, page in), effectively doubling the time required to process a page fault. This can be alleviated somewhat by assigning a “modify bit”, or “dirty bit” to each page, indicating whether or not it has been changed since it was last loaded in from disk. If the dirty bit has not been set, then the page is unchanged, and does not need to be written out to disk. Otherwise the page write is required.
There are two major requirements to implement a successful demand paging system. We must develop a frame-allocation algorithm and a page-replacement algorithm.
Frame Allocation algorithms
The absolute minimum number of frames that a process must be allocated is dependent on system architecture, and corresponds to the worst-case scenario of the number of pages that could be touched by a single machine instruction.
-
Equal Allocation: If there are m frames available and n processes to share them, each process gets m/n frames, and the leftovers are kept in a free-frame buffer pool.
-
Proportional Allocation: Allocate the frames proportionally to the size of the process, relative to the total size of all processes.
Non Uniform Memoery Access (NUMA)
The above arguments all assume that all memory is equivalent, or at least has equivalent access times. This may not be the case in multiple-processor systems, especially where each CPU is physically located on a separate circuit board which also holds some portion of the overall system memory. In these latter systems, CPUs can access memory that is physically located on the same board much faster than the memory on the other boards.
The basic solution is akin to processor affinity - At the same time that we try to schedule processes on the same CPU to minimize cache misses, we also try to allocate memory for those processes on the same boards, to minimize access times.
Page Replacement Algorithms
FIFO Page Replacement
- As new pages are brought in, they are added to the tail of a queue, and the page at the head of the queue is the next victim.
- Although FIFO is simple and easy, it is not always optimal, or even efficient.
- An interesting effect that can occur with FIFO is Belady’s anomaly, in which increasing the number of frames available can actually increase the number of page faults that occur!
The discovery of Belady’s anomaly lead to the search for an optimal page-replacement algorithm, which is simply that which yields the lowest of all possible page-faults.
OPT or MIN
- This algorithm is simply “Replace the page that will not be used for the longest time in the future”.
- Unfortunately OPT cannot be implemented in practice, because it requires foretelling the future, but it makes a nice benchmark for the comparison and evaluation of real proposed new algorithms.
LRU Page Replacement
- Least Recently Used algorithm states that the page that has not been used in the longest time is the one that will not be used again in the near future.
- Note the distinction between FIFO and LRU: The former looks at the oldest load time, and the latter looks at the oldest use time.
- LRU is considered a good replacement policy, and is often used. The problem is how exactly to implement it. There are two simple approaches commonly used:
- Counters: Every memory access increments a counter, and the current value of this counter is stored in the page table entry for that page. Then finding the LRU page involves simple searching the table for the page with the smallest counter value.
- Stack: Another approach is to use a stack, and whenever a page is accessed, pull that page from the middle of the stack and place it on the top. The LRU page will always be at the bottom of the stack. Because this requires removing objects from the middle of the stack, a doubly linked list is the recommended data structure.
Second-Chance Algorithm
- The second chance algorithm is essentially a FIFO, except the reference bit is used to give pages a second chance at staying in the page table.
- When a page must be replaced, the page table is scanned in a FIFO (circular queue) manner. If a page is found with its reference bit not set, then that page is selected as the next victim. If, however, the next page in the FIFO does have its reference bit set, then it is given a second chance:
- The reference bit is cleared, and the FIFO search continues.
- If some other page is found that did not have its reference bit set, then that page will be selected as the victim, and this page (the one being given the second chance) will be allowed to stay in the page table.
- If, however, there are no other pages that do not have their reference bit set, then this page will be selected as the victim when the FIFO search circles back around to this page on the second pass.
Counting-Based Page Replacement
- Least Frequently Used, LFU: Replace the page with the lowest reference count. A problem can occur if a page is used frequently initially and then not used any more, as the reference count remains high. A solution to this problem is to right-shift the counters periodically, yielding a time-decaying average reference count.
- Most Frequently Used, MFU: Replace the page with the highest reference count. The logic behind this idea is that pages that have already been referenced a lot have been in the system a long time, and we are probably done with them, whereas pages referenced only a few times have only recently been loaded, and we still need them.
- In general counting-based algorithms are not commonly used, as their implementation is expensive and they do not approximate OPT well.
Memory Protection
- The page table can also help to protect processes from accessing memory that they shouldn’t, or their own memory in ways that they shouldn’t.
- A bit or bits can be added to the page table to classify a page as read-write, read-only, read-write-execute, or some combination of these sorts of things. Then each memory reference can be checked to ensure it is accessing the memory in the appropriate mode.
- “Valid”/“invalid” bits can be added to “mask off” entries in the page table that are not in use by the current process.
Shared Pages
- Paging systems can make it very easy to share blocks of memory, by simply duplicating page numbers in multiple page frames.
- If code is reentrant, that means that it does not write to or change the code in any way (it is non self-modifying), and it is therefore safe to re-enter it. More importantly, it means the code can be shared by multiple processes, so long as each has their own copy of the data and registers, including the instruction register.
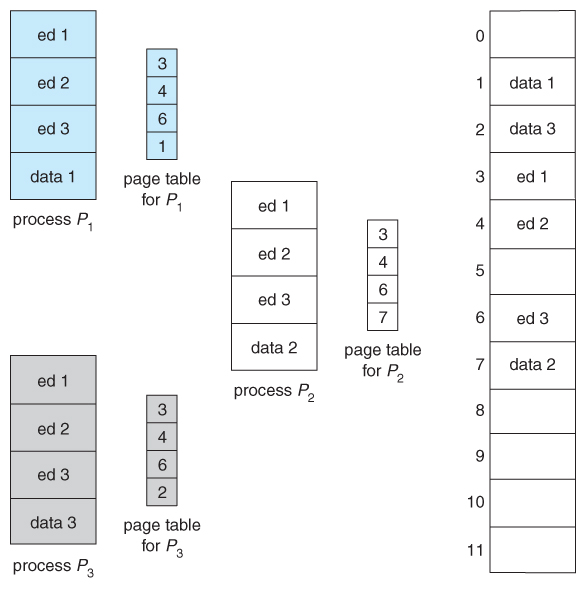
Multi-level Paging
- Most modern computer systems support logical address spaces of
2^32to2^64. - With a
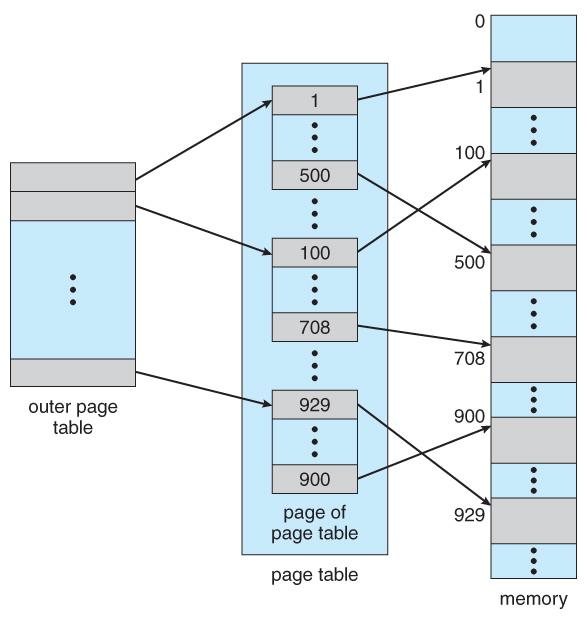
2^32address space and4K(2^12) page sizes, this leave2^20entries in the page table. At 4 bytes per entry, this amounts to a 4 MB page table, which is too large to reasonably keep in contiguous memory. (And to swap in and out of memory with each process switch.) Note that with 4K pages, this would take 1024 pages just to hold the page table! - One option is to use a two-tier paging system, i.e. to page the page table.
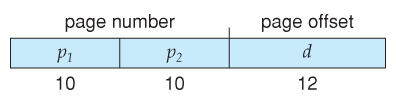
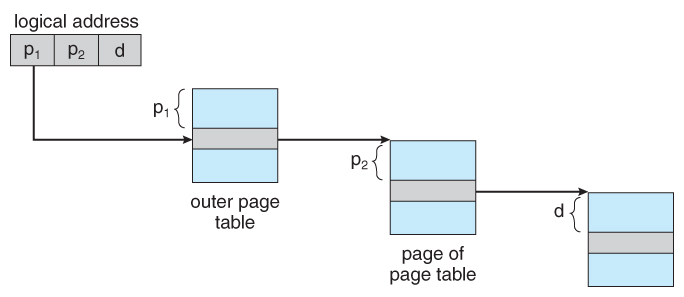
- For example, the 20 bits described above could be broken down into two 10-bit page numbers. The first identifies an entry in the outer page table, which identifies where in memory to find one page of an inner page table. The second 10 bits finds a specific entry in that inner page table, which in turn identifies a particular frame in physical memory. (The remaining 12 bits of the 32 bit logical address are the offset within the 4K frame.)
Inverted Page Tables
- Instead of a table listing all of the pages for a particular process, an inverted page table lists all of the pages currently loaded in memory, for all processes. (i.e. there is one entry per frame instead of one entry per page.) *** Access to an inverted page table can be slow**, as it may be necessary to search the entire table in order to find the desired page (or to discover that it is not there.) Hashing the table can help speedup the search process.
- Inverted page tables prohibit the normal method of implementing shared memory, which is to map multiple logical pages to a common physical frame. (Because each frame is now mapped to one and only one process).

Memory-Mapped Files
Rather than accessing data files directly via the file system with every file access, data files can be paged into memory the same as process files, resulting in much faster accesses. his is known as memory-mapping a file.
- Basically a file is mapped to an address range within a process’s virtual address space, and then paged in as needed using the ordinary demand paging system.
- Note that file writes are made to the memory page frames, and are not immediately written out to disk. (Use
flush()system call). This is also why it is important toclose()a file when one is done writing to it - So that the data can be safely flushed out to disk and so that the memory frames can be freed up for other purposes.
Memory-Mapped I/O
- All access to devices is done by writing into (or reading from) the device’s registers. Normally this is done via special I/O instructions. For certain devices it makes sense to simply map the device’s registers to addresses in the process’s virtual address space, making device I/O as fast and simple as any other memory access. Video controller cards are a classic example of this.
- Serial and parallel devices can also use memory mapped I/O, mapping the device registers to specific memory addresses known as I/O Ports:
- Programmed I/O (PIO), also known as polling: The CPU periodically checks the control bit on the device, to see if it is ready to handle another byte of data.
- Interrupt Driven: The device generates an interrupt when it either has another byte of data to deliver or is ready to receive another byte.
Kernel Memory Allocation
Memory allocated to the kernel cannot be so easily paged. For eg., some of it is used for I/O buffering and direct access by devices, and must therefore be contiguous and not affected by paging. Other memory is used for internal kernel data structures of various sizes, and since kernel memory is often locked (restricted from being ever swapped out), management of this resource must be done carefully to avoid internal fragmentation.
-
Buddy System: The Buddy System allocates memory using a power of two allocator. Under this scheme, memory is always allocated as a power of 2 ( 4K, 8K, 16K, etc ), rounding up to the next nearest power of two if necessary.
-
Slab Allocation: This allocates memory to the kernel in chunks called slabs, consisting of one or more contiguous pages. The kernel then creates separate caches for each type of data structure it might need from one or more slabs. Initially the caches are marked empty, and are marked full as they are used. New requests for space in the cache is first granted from empty or partially empty slabs, and if all slabs are full, then additional slabs are allocated.
Share this post
Twitter
Facebook
Reddit
LinkedIn
Email