Short Notes: cGroups and Namespaces
Diving deep into the internals of containerization.
Cgroups
Control groups (or cgroups as they are commonly known) are a feature provided by the Linux kernel to track, manage, restrict, and audit groups of processes. It also allows to limit/prioritize what resources are available to a group of processes. The way you interact with cgroups are by using sub-systems; cgroup system is an abstract framework, subsystems are the concrete implementation. Cgroups are more flexible as they can operate on (sub)sets of processes (possibly with different system users).
Different subsystems can organized processes seperately and are independent of each other. This means a a single cpu cgroup could be assigned to 2 processes, but both processes might have different memory cgroups. Some of the main cgroups include:
cpu- uses the scheduler to provide cgroup tasks access to the processor resourcesio- sets limit to read/write from/to block devicesmemory- sets limit on memory usage by a task(s) from a groupdevices- allows access to devices by a task(s) from a groupfreezer- allows to suspend/resume for a task(s) from a groupnet_cls- allows to mark network packets from task(s) from a group; network interface for a grouppid- sets limit to number of processes in a group
All subsystems are arranged in a tree like hierarchy; all running processes are represented exactly once in each subsustem.
New Processes inherit the cgroups from their parents. The cgroup name of a process can be found in /proc/PID/cgroup. The systemd-cgtop command can be used to see the resource usage.
Cgroups can be used with service files. CPU slices can be created for services; They must be placed in a systemd directory, such as /etc/systemd/system/.
## /etc/systemd/system/my.slice
[Slice]
CPUQuota=30%
Cgroup limits can be added to the service files:
[Service]
Slice=my.slice
MemoryMax=1G
Unprivileged users can divide the resources provided to them into new cgroups, if some conditions are met. Cgroups v2 must be utilized for a non-root user to be allowed managing cgroup resources. Not all resources can be controlled by the user.

For user to control cpu and io resources, the resources need to be delegated. This can be done with a drop-in file. For example if your user id is 1000:
# /etc/systemd/system/user@1000.service.d/delegate.conf
[Service]
Delegate=cpu cpuset io
Reboot and verify that the slice your user session is under has cpu and io controller:
$ cat /sys/fs/cgroup/user.slice/user-1000.slice/cgroup.controllers
cpuset cpu io memory pids
You can create “ad-hoc” groups on the fly. You can even grant the privileges to create custom groups to regular users. If you are user and groupname is the cgroup name, then
# cgcreate -a user -t user -g memory,cpu:groupname
makes all the tunables in the group groupname writable by user.
cgroup virtual filesystem
Cgroups are powerful, and thanks to virtual filesystems, it can be managed very easily using the cgroup virtual filesystem. You can create a new cgroup by simply creating directories in the /sys/fs/cgroup virtual filesystems under any given subsystem. The value(limit) of the cgroup can be set by simply writing the value in the related file in the cgroup directory. A process can be moved to a new cgroup by simply adding it in the cgroup.procs file (or the tasks file) in the cgroup.
Difference b/w cgroups.procs vs tasks is that there are some multithreaded processes in your cpuset. In the cgroup.procs file, each such process apears only once (listed by its TGID). In the tasks file, each thread appears once (listed by its PID).
Examples:
- Create a new memory subsystem cgroup named
groupname
# mkdir /sys/fs/cgroup/memory/groupname
- Set the maximum memory limit to
100MB
# echo 100000000 > /sys/fs/cgroup/memory/groupname/memory.limit_in_bytes
- Move a process with process id
pidto the cgroup
# echo pid > /sys/fs/cgroup/memory/groupname/cgroup.procs
- Check cgroups of a process
# cat /proc/$$/cgroup
10:memory:/groupname
9:blkio:/user.slice/user-1000.slice
8:net_cls,net_prio:/
7:cpu,cpuacct:/user.slice/user-1000.slice
6:perf_event:/
5:freezer:/
4:cpuset:/
3:pids:/user.slice/user-1000.slice
2:devices:/user.slice/user-1000.slice
1:name=systemd:/user.slice/user-1000.slice/session-3.scope
- Limit a cgroup
new_pidgroupto two processes, put your bash shell within the cgroup so you cannot spawn more than 2 processes:
# mkdir /sys/fs/cgroup/pids/new_pidgroup
# echo 2 > /sys/fs/cgroup/pids/new_pidgroup/pids.max
# echo $$ | tee /sys/fs/cgroup/pids/new_pidgroup/tasks
# cat /sys/fs/cgroup/pids/new_pidgroup/tasks
1289
1315
# $(cat /sys/fs/cgroup/pids/new_pidgroup/tasks)
- bash: fork: retry: No child processes
- bash: fork: retry: No child processes
- bash: fork: retry: No child processes
....
Docker create a new cgroup docker in all the cgroup subsystems, and has all metering done from the docker hierarcy.
- Eg. running an nginx container with cpu slices, we can find the container shares in the docker cgroup in the cpu subsystem
$ docker run --cpu-shares 256 --rm --name nginx nginx sleep 300
3773d3134b123e1623.....
$ docker exec nginx cat /sys/fs/cgroup/cpu/cpu.shares
256
$ cat /sys/fs/cgroup/cpu/docker/3773d3134b123e1623...../cpu.shares
256
Namespaces
A namespace wraps a global system resource in an abstraction that makes it appear to the processes within the namespace that they have their own isolated instance of the global resource. Changes to the global resource are visible to other processes that are members of the namespace, but are invisible to other processes. Namespaces can provide even fine-grained isolation, allowing process A and B to share some system resources (e.g. sharing a mount point or a network stack).
Namespaces are often used when untrusted code has to be executed on a given machine without compromising the host OS. The namespaces are per-process attributes. Each process can perceive at most one namespace of a kind. The kernel assigns each process a symbolic link per namespace kind in /proc/<pid>/ns/. The inode number pointed to by this symlink is the same for each process in this namespace. This uniquely identifies each namespace by the inode number pointed to by one of its symlinks.
Unlike cgroups, namespaces cannot be alloted to the processes using the virtual filesystems. Namespaces are set using following system calls:
-
clone(2)- Used for creating a new process and putting it in a given namespace.
- If the
flagsargument of the call specifies one or more of namespace flags, then new namespaces are created for each flag, and the child process is made a member of those namespaces.
-
unshare(2)- Used for an already existing process, this system call moves the calling process to a new namespace.
- If the flags argument of the call specifies one or more of the namespace flags, then new namespaces are created for each flag, and the calling process is made a member of those namespaces.
-
setns(2)- Allows the calling process to join an existing namespace.
- The namespace to join is specified via a file descriptor that refers to one of the
/proc/pid/nsnamespaces.
Each process has a /proc/<pid>/ns/ subdirectory containing one entry for each namespace that supports being manipulated by setns(2).
Following namespaces are available on linux that isolates different resources:
-
Cgroup: Cgroup root
- The cgroup namespace type hides the identity of the control group of which process is a member.
- A process in such a namespace, checking which control group any process is part of, would see a path that is actually relative to the control group set at creation time, hiding its true control group position and identity.
-
IPC: System V IPC, POSIX message queues
- IPC namespaces isolate processes from SysV style inter-process communication.
- This prevents processes in different IPC namespaces from using, for example, the SHM family of functions to establish a range of shared memory between the two processes. Instead, each process will be able to use the same identifiers for a shared memory region and produce two such distinct regions.
-
Network: Network devices, stacks, ports, etc.
- Network namespaces virtualize the network stack. On creation, a network namespace contains only a loopback interface.
- Each network interface (physical or virtual) is present in exactly 1 namespace and can be moved between namespaces.
- Each namespace will have a private set of IP addresses, its own routing table, socket listing, connection tracking table, firewall, and other network-related resources.
- Destroying a network namespace destroys any virtual interfaces within it and moves any physical interfaces within it back to the initial network namespace.
- In order to make a process inside a new network namespace reachable from another network namespace, a pair of virtual interfaces is needed (
vethpair). - Communication between isolated network stacks in the same namespace is done using a bridge.
-
Mount: Mount points
- Upon creation the mounts from the current mount namespace are copied to the new namespace, but mount points created afterwards do not propagate between namespaces.
-
PID: Process IDs
- PID namespaces are nested, meaning when a new process is created it will have a PID for each namespace from its current namespace up to the initial PID namespace.
- Hence the initial PID namespace is able to see all processes, albeit with different PIDs than other namespaces will see processes with.
- The first process created in a PID namespace is assigned the process ID number 1 and receives most of the same special treatment as the normal
initprocess, most notably that orphaned processes within the namespace are attached to it. unsharecalls without forking will fail.- If you run unshare without
--fork, bash will have the samepidas the current “unshare” process. The current “unshare” process makes theunsharesystemcall, creates a new pid namespace, but the current “unshare” process is not in the new pid namespace. It is the desired behavior of linux kernel: process A creates a new namespace, the process A itself won’t be put into the new namespace, only the sub-processes of process A will be put into the new namespace.
- If you run unshare without
-
Time:
- The time namespace allows processes to see different system times in a way similar to the UTS namespace.
-
User: User and group IDs
- User namespaces are a feature to provide both privilege isolation and user identification segregation across multiple sets of processes.
- Like the PID namespace, user namespaces are nested and each new user namespace is considered to be a child of the user namespace that created it.
- A user namespace contains a mapping table converting user IDs from the container’s point of view to the system’s point of view.
- To facilitate privilege isolation of administrative actions, each namespace type is considered owned by a user namespace based on the active user namespace at the moment of creation.
- A user with administrative privileges in the appropriate user namespace will be allowed to perform administrative actions within that other namespace type.
- Hence the initial user namespace has administrative control over all namespace types in the system.
- If a user ID has no mapping inside the namespace, then system calls that return user IDs return the value defined in the file
/proc/sys/kernel/overflowuid, which on a standard system defaults to the value65534. Initially, a user namespace has no user ID mapping, so all user IDs inside the namespace map to this value. - Some processes need to run under effective
UID 0in order to provide their services and be able to interact with the OS file system. One of the most common things when using user namespaces is to define mappings. This is done using the/proc/<PID>/uid_mapand/proc/<PID>/gid_mapfiles.
-
UTS: Hostname and NIS domain name
- UTS (UNIX Time-Sharing) namespaces allow a single system to appear to have different host and domain names to different processes.
- When a process creates a new UTS namespace, the hostname and domain of the new UTS namespace are copied from the corresponding values in the caller’s UTS namespace.
On system boot, the first process started on most of the modern Linux OS is systemd (system daemon), which is situated on the root node of the tree. Its parent is PID=0 which is a non-existing process in the OS.
$ ls -l /proc/$$/ns | awk '{print $1, $9, $10, $11}'
total 0
lrwxrwxrwx. cgroup -> cgroup:[4026531835]
lrwxrwxrwx. ipc -> ipc:[4026531839]
lrwxrwxrwx. mnt -> mnt:[4026531840]
lrwxrwxrwx. net -> net:[4026531969]
lrwxrwxrwx. pid -> pid:[4026531836]
lrwxrwxrwx. pid_for_children -> pid:[4026531834]
lrwxrwxrwx. time -> time:[4026531834]
lrwxrwxrwx. time_for_children -> time:[4026531834]
lrwxrwxrwx. user -> user:[4026531837]
lrwxrwxrwx. uts -> uts:[4026531838]
Bind mounting one of these files in this directory to somewhere else in the filesystem keeps the corresponding namespace of the process specified by pid alive even if all processes currently in the namespace terminate. As long as this file descriptor remains open, the namespace will remain alive, even if all processes in the namespace terminate. Namespaces are automatically torn down when the last process in the namespace terminates or leaves the namespace. If two processes are in the same namespace, then the device IDs and inode numbers of their /proc/pid/ns/xxx symbolic links will be the same.
Namespaces can be pinned into existence with no members by doing the following:
- An open file descriptor or a bind mount exists for the corresponding
/proc/pid/ns/*file. - The namespace is hierarchical (i.e., a PID or user namespace), and has a child namespace.
- It is a user namespace that owns one or more nonuser namespaces.
- It is a
PIDnamespace, and there is a process that refers to the namespace via a/proc/pid/ns/pid_for_childrensymbolic link. - It is a
timenamespace, and there is a process that refers to the namespace via a/proc/pid/ns/time_for_childrensymbolic link. - It is a
PIDnamespace, and a corresponding mount of aproc(5)filesystem refers to this namespace.
Union Filesystems
Unionfs is a filesystem service for Linux, FreeBSD and NetBSD which implements a union mount for other file systems. It allows files and directories of separate file systems, known as branches, to be transparently overlaid, forming a single coherent file system. Contents of directories which have the same path within the merged branches will be seen together in a single merged directory, within the new, virtual filesystem. A container is composed of multiple layers. A sandbox of a container is composed of one or more image layers and a container layer. Container layer is writable, image layers are read-only.
Challenges with conventional filesystems
- Inefficient Disk Space Utilization
- If you have 10 python applications with an image size of 500M, a concrete file-systems like
ext*orNFSfor containers, at least 5G of space is used by having redundant data.
- If you have 10 python applications with an image size of 500M, a concrete file-systems like
- Latency in bootstrap
- A container is nothing but a process. The only way to create a new process is forking the existing process.
- The fork operation creates a separate address space and has an exact copy of all the memory segments of the parent process.
- In order to create a new container, all the files of image layers would be copied into container namespace. If a huge payload is needed to be copied at the time of starting a container it increases the bootstrap time of a container.
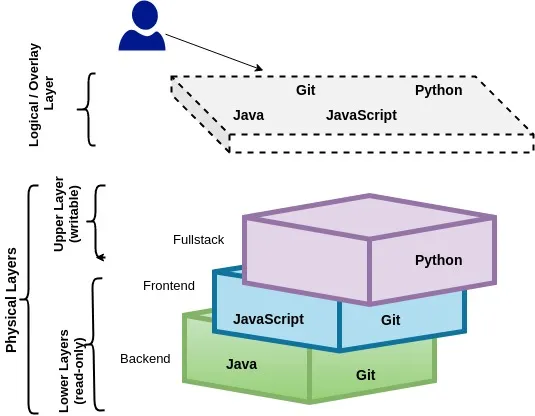
Union file system works on top of the other file-systems. It gives a single coherent and unified view to files and directories of separate file-system. In other words, it mounts multiple directories to a single root. It is more of a mounting mechanism than a file system. Overlay or merge layer sits On top of all the directories and provides a logical, coherent and unified view of multiple physical directories to the application.
# frontend, backend, fullstack are vfs, fullstack/workdir is a directory
mount -t overlay -o lowerdir=frontend:backend,upperdir=fullstack/upper,workdir=fullstack/workdir none union
Properties of UnionFS
- Logical merge of multiple layers.
- Read-only lower layers, writable upper layer.
- Copy on Write (CoW)
- Simulate removal from lower directory through “whiteout” file. This file exists only within the “union” directory, without physically appearing in either the “upper” or “lower” directories.
OverlayFS
With the overlayFS, 4 directories must exist beforehand:
-
Base Layer (Read Only)
- This is where the base files for your file system are stored, this layer is read only. If you want to think about this in terms of Docker images you can think of this layer as your base image.
-
Overlay Layer (Main User View)
- Overlay layer is where the user operates.
- Gives the user the ability to interact and “write” on files.
- When you write to this layer changes are stored in our next layer.
- When changes are made this layer will offer a union view of the Base and Diff layer with the Diff layer’s files superseding the Base layer’s.
-
Diff Layer
- Any changes made in the Overlay Layer are automatically stored in this layer.
- Whenever you write to something that’s already found in the base layer the overlay(fs) will copy the file over to the Diff Layer and then make the modifcations you just tried to write (CoW).
Share this post
Twitter
Facebook
Reddit
LinkedIn
Email